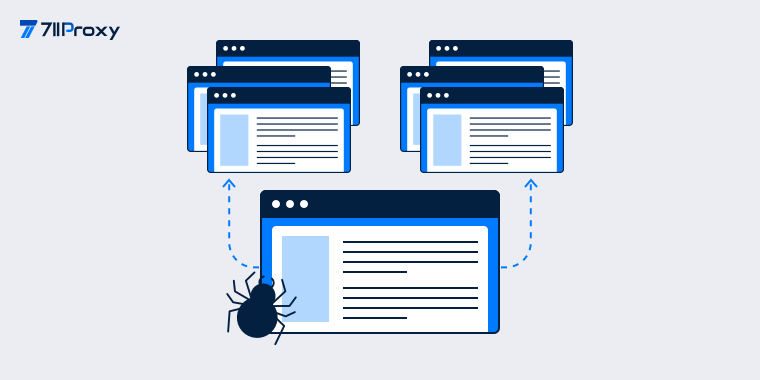
<p style="line-height: 2em;"><span style="font-size: 16px;">GitHub is the world's largest code hosting platform, bringing together millions of open-source projects and tens of millions of developers. It serves as a valuable resource for accessing technology trends and open-source data.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><strong><span style="font-size: 24px;">The Value of GitHub Repository Data</span></strong></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><a href="https://www.711proxy.com/use-cases/data-scraping" target="_self" style="font-size: 16px; color: rgb(0, 176, 240); text-decoration: underline;"><strong><span style="font-size: 16px; color: rgb(0, 176, 240);">GitHub</span></strong></a><span style="font-size: 16px;"> hosts a vast array of open-source projects. Metadata within repositories, such as star counts, fork numbers, and programming language distribution, holds immense value for analysis and research. By scraping this information in a compliant manner, we can achieve multiple objectives:</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">· Track the evolution of popular projects within specific technology domains.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;">· Build high-quality open-source datasets to support academic research.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;">· Discover high-quality codebases and useful tools or frameworks.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;">· Analyze the community activity and growth trends of different programming languages.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">These data-driven insights enable developers, researchers, and businesses to make more informed and forward-looking technology selection decisions.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><strong><span style="font-size: 24px;">Common Scraping Challenges</span></strong></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">In practice, unstable network conditions are often the primary cause of failure when scraping GitHub repository information. Cross-border network links can be highly volatile, and latency when accessing the GitHub API varies significantly by region. Intermittent connection failures or request timeouts may occur in some areas. These issues not only interrupt the scraping process but also increase the time spent on debugging and restarting tasks.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">Additionally, GitHub enforces strict rate limits. Even for authenticated users, sending a high volume of requests in a short period can result in a 403 or 429 status code, temporarily blocking access from that IP address and causing the scraping request to fail.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><strong><span style="font-size: 24px;">Why <a href="https://www.711proxy.com/use-cases/data-scraping" target="_self" style="color: rgb(0, 176, 240); text-decoration: underline;"><span style="font-size: 24px; color: rgb(0, 176, 240);">Residential Proxies</span></a> Are Irreplaceable</span></strong></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">When choosing a proxy IP, some users may consider datacenter IPs due to budget constraints, but this approach has notable drawbacks. Datacenter IPs are often shared among multiple users. If one user triggers a restriction, others using the same IP can also be affected. Moreover, datacenter IP ranges are relatively concentrated and can suffer from significant network fluctuations, making stable connections difficult to guarantee.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">In contrast, residential proxies with clear, legitimate sources are clearly the better choice. Assigned by legitimate internet service providers, these real IPs offer stable bandwidth and a higher level of trust from platforms. With regular management by professional operations teams, not only is IP availability significantly higher, but overall performance is also reliably ensured.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><strong><span style="font-size: 24px;">711Proxy: The Best Proxy for Data Scraping</span></strong></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><a href="https://www.711proxy.com/global-residential-proxy-locations" target="_self" style="font-size: 16px; color: rgb(0, 176, 240); text-decoration: underline;"><strong><span style="font-size: 16px; color: rgb(0, 176, 240);">711Proxy</span></strong></a><span style="font-size: 16px;">, as a professional residential proxy provider, offers real residential IPs covering over 200 countries and regions worldwide. Its IP pool is regularly maintained and updated, achieving an availability rate of up to 99.9%. For large-scale scraping tasks, 711Proxy supports unlimited concurrent requests, easily handling the high-frequency call demands of the GitHub API and preventing scraping interruptions due to rate limiting or connection timeouts.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">Furthermore, 711Proxy is compatible with both HTTP and SOCKS5 protocols, adapting to various scraping frameworks and tools. Whether using Python libraries like Requests or Scrapy, or working with other programming environments, you can quickly complete configuration and integration.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><strong><span style="font-size: 24px;">Additional Considerations</span></strong></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">When scraping GitHub repository information, it is recommended to prioritize the use of the official API and strictly adhere to the platform's access rules. Select appropriate network nodes based on your scraping needs, regularly check your request configurations and token status, and optimize your request logic to avoid unnecessary calls. This ensures your scraping activities remain compliant, efficient, and reliable.</span></p><p style="line-height: 2em;"><span style="font-size: 16px;"> </span></p><p style="line-height: 2em;"><span style="font-size: 16px;">Visit the <a href="https://www.711proxy.com/pricing/regular/residential-proxies-gb" target="_self" style="color: rgb(0, 176, 240); text-decoration: underline;"><strong><span style="font-size: 16px; color: rgb(0, 176, 240);">711Proxy</span></strong></a> official website to make your data scraping more compliant, efficient, and reliable.</span></p><p><br/></p>
























'%3e%3cg%20id='ic/首页/向上'%20transform='translate(377,%20156)%20scale(1,%20-1)%20rotate(-90)%20translate(-377,%20-156)translate(370,%20149)'%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='14'%20height='14'%3e%3c/rect%3e%3cpolyline%20id='路径'%20stroke='%23042040'%20transform='translate(7,%207.5)%20scale(1,%20-1)%20translate(-7,%20-7.5)'%20points='12%205%207%2010%202%205'%3e%3c/polyline%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)